Download the Jupyter Notebook for this section: post_estimation.ipynb
Post-Estimation Tutorial¶
[1]:
%matplotlib inline
import pyblp
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
pyblp.options.digits = 2
pyblp.options.verbose = False
pyblp.__version__
[1]:
'1.2.0'
This tutorial covers several features of pyblp which are available after estimation including:
Calculating elasticities and diversion ratios.
Calculating marginal costs and markups.
Computing the effects of mergers: prices, shares, and HHI.
Using a parametric bootstrap to estimate standard errors.
Estimating optimal instruments.
Constructing optimal micro moments.
Problem Results¶
As in the fake cereal tutorial, we’ll first solve the fake cereal problem from Nevo (2000a). We load the fake data and estimate the model as in the previous tutorial. We output the setup of the model to confirm we have correctly configured the Problem
[2]:
product_data = pd.read_csv(pyblp.data.NEVO_PRODUCTS_LOCATION)
agent_data = pd.read_csv(pyblp.data.NEVO_AGENTS_LOCATION)
product_formulations = (
pyblp.Formulation('0 + prices', absorb='C(product_ids)'),
pyblp.Formulation('1 + prices + sugar + mushy')
)
agent_formulation = pyblp.Formulation('0 + income + income_squared + age + child')
problem = pyblp.Problem(product_formulations, product_data, agent_formulation, agent_data)
problem
[2]:
Dimensions:
=================================================
T N F I K1 K2 D MD ED
--- ---- --- ---- ---- ---- --- ---- ----
94 2256 5 1880 1 4 4 20 1
=================================================
Formulations:
===================================================================
Column Indices: 0 1 2 3
----------------------------- ------ -------------- ----- -----
X1: Linear Characteristics prices
X2: Nonlinear Characteristics 1 prices sugar mushy
d: Demographics income income_squared age child
===================================================================
We’ll solve the problem in the same way as before. The Problem.solve method returns a ProblemResults class, which displays basic estimation results. The results that are displayed are simply formatted information extracted from various class attributes such as ProblemResults.sigma and ProblemResults.sigma_se.
[3]:
initial_sigma = np.diag([0.3302, 2.4526, 0.0163, 0.2441])
initial_pi = [
[ 5.4819, 0, 0.2037, 0 ],
[15.8935, -1.2000, 0, 2.6342],
[-0.2506, 0, 0.0511, 0 ],
[ 1.2650, 0, -0.8091, 0 ]
]
results = problem.solve(
initial_sigma,
initial_pi,
optimization=pyblp.Optimization('bfgs', {'gtol': 1e-5}),
method='1s'
)
results
[3]:
Problem Results Summary:
=======================================================================================================
GMM Objective Gradient Hessian Hessian Clipped Weighting Matrix Covariance Matrix
Step Value Norm Min Eigenvalue Max Eigenvalue Shares Condition Number Condition Number
---- --------- -------- -------------- -------------- ------- ---------------- -----------------
1 +4.6E+00 +6.9E-06 +5.1E-05 +1.6E+04 0 +6.9E+07 +8.4E+08
=======================================================================================================
Cumulative Statistics:
===========================================================================
Computation Optimizer Optimization Objective Fixed Point Contraction
Time Converged Iterations Evaluations Iterations Evaluations
----------- --------- ------------ ----------- ----------- -----------
00:00:39 Yes 51 57 46379 143975
===========================================================================
Nonlinear Coefficient Estimates (Robust SEs in Parentheses):
=====================================================================================================================
Sigma: 1 prices sugar mushy | Pi: income income_squared age child
------ ---------- ---------- ---------- ---------- | ------ ---------- -------------- ---------- ----------
1 +5.6E-01 | 1 +2.3E+00 +0.0E+00 +1.3E+00 +0.0E+00
(+1.6E-01) | (+1.2E+00) (+6.3E-01)
|
prices +0.0E+00 +3.3E+00 | prices +5.9E+02 -3.0E+01 +0.0E+00 +1.1E+01
(+1.3E+00) | (+2.7E+02) (+1.4E+01) (+4.1E+00)
|
sugar +0.0E+00 +0.0E+00 -5.8E-03 | sugar -3.8E-01 +0.0E+00 +5.2E-02 +0.0E+00
(+1.4E-02) | (+1.2E-01) (+2.6E-02)
|
mushy +0.0E+00 +0.0E+00 +0.0E+00 +9.3E-02 | mushy +7.5E-01 +0.0E+00 -1.4E+00 +0.0E+00
(+1.9E-01) | (+8.0E-01) (+6.7E-01)
=====================================================================================================================
Beta Estimates (Robust SEs in Parentheses):
==========
prices
----------
-6.3E+01
(+1.5E+01)
==========
Additional post-estimation outputs can be computed with ProblemResults methods.
Elasticities and Diversion Ratios¶
We can estimate elasticities, \(\varepsilon\), and diversion ratios, \(\mathscr{D}\), with ProblemResults.compute_elasticities and ProblemResults.compute_diversion_ratios.
As a reminder, elasticities in each market are
Diversion ratios are
Following Conlon and Mortimer (2021), we report the diversion to the outside good \(D_{j0}\) on the diagonal instead of \(D_{jj}=-1\).
[4]:
elasticities = results.compute_elasticities()
diversions = results.compute_diversion_ratios()
Post-estimation outputs are computed for each market and stacked. We’ll use matplotlib functions to display the matrices associated with a single market.
[5]:
single_market = product_data['market_ids'] == 'C01Q1'
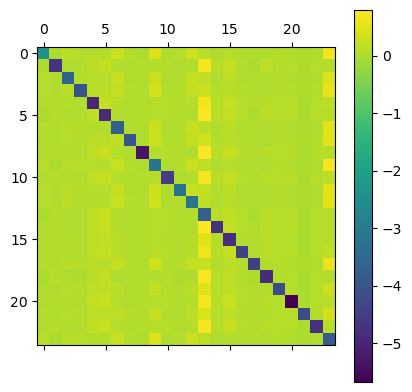
plt.colorbar(plt.matshow(elasticities[single_market]));
[6]:
plt.colorbar(plt.matshow(diversions[single_market]));
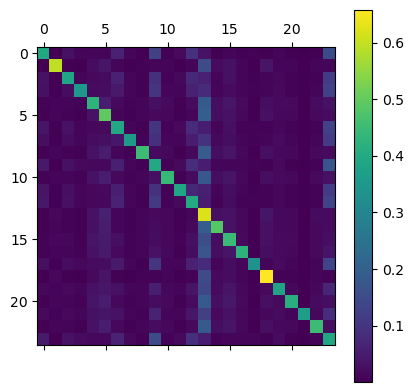
The diagonal of the first image consists of own elasticities and the diagonal of the second image consists of diversion ratios to the outside good. As one might expect, own price elasticities are large and negative while cross-price elasticities are positive but much smaller.
Elasticities and diversion ratios can be computed with respect to variables other than prices with the name argument of ProblemResults.compute_elasticities and ProblemResults.compute_diversion_ratios. Additionally,
ProblemResults.compute_long_run_diversion_ratios can be used to used to understand substitution when products are eliminated from the choice set.
The convenience methods ProblemResults.extract_diagonals and ProblemResults.extract_diagonal_means can be used to extract information about own elasticities of demand from elasticity matrices.
[7]:
means = results.extract_diagonal_means(elasticities)
An alternative to summarizing full elasticity matrices is to use ProblemResults.compute_aggregate_elasticities to estimate aggregate elasticities of demand, \(E\), in each market, which reflect the change in total sales under a proportional sales tax of some factor.
[8]:
aggregates = results.compute_aggregate_elasticities(factor=0.1)
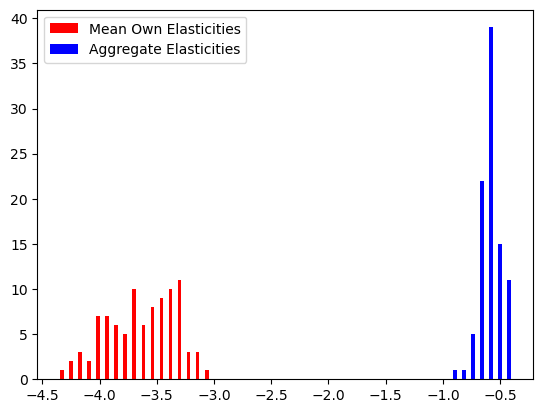
Since demand for an entire product category is generally less elastic than the average elasticity of individual products, mean own elasticities are generally larger in magnitude than aggregate elasticities.
[9]:
plt.hist(
[means.flatten(), aggregates.flatten()],
color=['red', 'blue'],
bins=50
);
plt.legend(['Mean Own Elasticities', 'Aggregate Elasticities']);
Marginal Costs and Markups¶
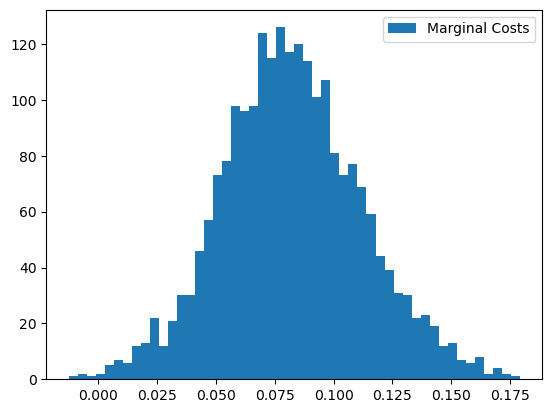
To compute marginal costs, \(c\), the product_data passed to Problem must have had a firm_ids field. Since we included firm IDs when configuring the problem, we can use ProblemResults.compute_costs.
[10]:
costs = results.compute_costs()
plt.hist(costs, bins=50);
plt.legend(["Marginal Costs"]);
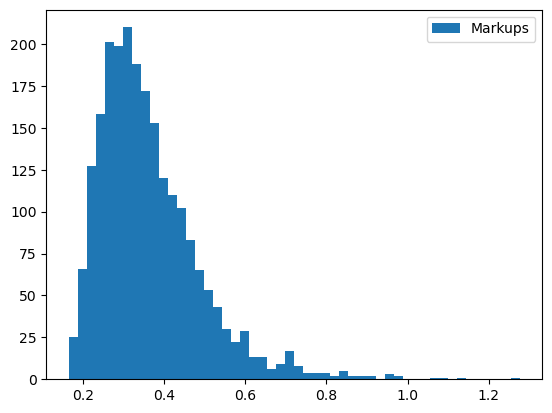
Other methods that compute supply-side outputs often compute marginal costs themselves. For example, ProblemResults.compute_markups will compute marginal costs when estimating markups, \(\mathscr{M}\), but computation can be sped up if we just use our pre-computed values.
[11]:
markups = results.compute_markups(costs=costs)
plt.hist(markups, bins=50);
plt.legend(["Markups"]);
Mergers¶
Before computing post-merger outputs, we’ll supplement our pre-merger markups with some other outputs. We’ll compute Herfindahl-Hirschman Indices, \(\text{HHI}\), with ProblemResults.compute_hhi; population-normalized gross expected profits, \(\pi\), with ProblemResults.compute_profits; and population-normalized consumer surpluses, \(\text{CS}\), with ProblemResults.compute_consumer_surpluses.
[12]:
hhi = results.compute_hhi()
profits = results.compute_profits(costs=costs)
cs = results.compute_consumer_surpluses()
To compute post-merger outputs, we’ll create a new set of firm IDs that represent a merger of firms 2 and 1.
[13]:
product_data['merger_ids'] = product_data['firm_ids'].replace(2, 1)
We can use ProblemResults.compute_approximate_prices or ProblemResults.compute_prices to estimate post-merger prices. The first method, which is in the spirit of early approaches to merger evaluation such as Hausman, Leonard, and Zona (1994) and Werden (1997), is only a partial merger simulation in that it assumes shares and their price derivatives are unaffected by the merger.
The second method, which is used by Nevo (2000b), is a full merger simulation in that it does not make these assumptions, and is the preferred approach to merger simulation. By default, we iterate over the \(\zeta\)-markup equation from Morrow and Skerlos (2011) to solve the full system of \(J_t\) equations and \(J_t\) unknowns in each market \(t\). We’ll use the latter, since it is fast enough for this example problem.
[14]:
changed_prices = results.compute_prices(
firm_ids=product_data['merger_ids'],
costs=costs
)
We’ll compute post-merger shares with ProblemResults.compute_shares.
[15]:
changed_shares = results.compute_shares(changed_prices)
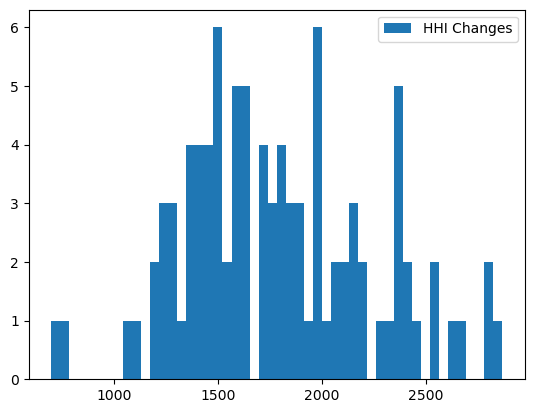
Post-merger prices and shares are used to compute other post-merger outputs. For example, \(\text{HHI}\) increases.
[16]:
changed_hhi = results.compute_hhi(
firm_ids=product_data['merger_ids'],
shares=changed_shares
)
plt.hist(changed_hhi - hhi, bins=50);
plt.legend(["HHI Changes"]);
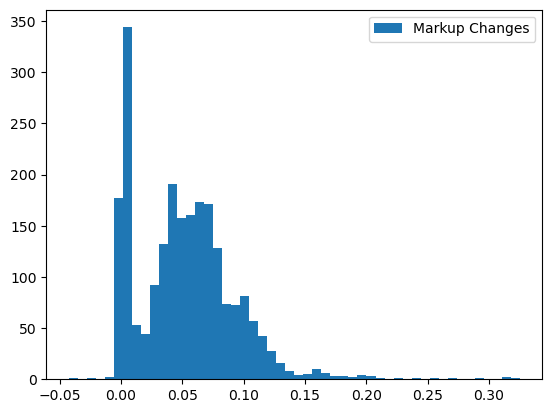
Markups, \(\mathscr{M}\), and profits, \(\pi\), generally increase as well.
[17]:
changed_markups = results.compute_markups(changed_prices, costs)
plt.hist(changed_markups - markups, bins=50);
plt.legend(["Markup Changes"]);
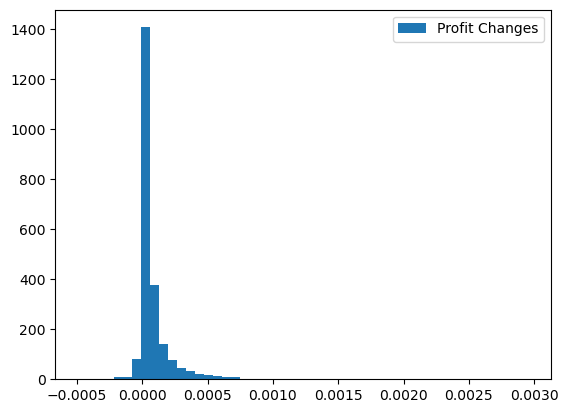
[18]:
changed_profits = results.compute_profits(changed_prices, changed_shares, costs)
plt.hist(changed_profits - profits, bins=50);
plt.legend(["Profit Changes"]);
On the other hand, consumer surpluses, \(\text{CS}\), generally decrease.
[19]:
changed_cs = results.compute_consumer_surpluses(changed_prices)
plt.hist(changed_cs - cs, bins=50);
plt.legend(["Consumer Surplus Changes"]);
Bootstrapping Results¶
Post-estimation outputs can be informative, but they don’t mean much without a sense sample-to-sample variability. One way to estimate confidence intervals for post-estimation outputs is with a standard bootstrap procedure:
Construct a large number of bootstrap samples by sampling with replacement from the original product data.
Initialize and solve a Problem for each bootstrap sample.
Compute the desired post-estimation output for each bootstrapped ProblemResults and from the resulting empirical distribution, construct boostrap confidence intervals.
Although appealing because of its simplicity, the computational resources required for this procedure are often prohibitively expensive. Furthermore, human oversight of the optimization routine is often required to determine whether the routine ran into any problems and if it successfully converged. Human oversight of estimation for each bootstrapped problem is usually not feasible.
A more reasonable alternative is a parametric bootstrap procedure:
Construct a large number of draws from the estimated joint distribution of parameters.
Compute the implied mean utility, \(\delta\), and shares, \(s\), for each draw. If a supply side was estimated, also computed the implied marginal costs, \(c\), and prices, \(p\).
Compute the desired post-estimation output under each of these parametric bootstrap samples. Again, from the resulting empirical distribution, construct boostrap confidence intervals.
Compared to the standard bootstrap procedure, the parametric bootstrap requires far fewer computational resources, and is simple enough to not require human oversight of each bootstrap iteration. The primary complication to this procedure is that when supply is estimated, equilibrium prices and shares need to be computed for each parametric bootstrap sample by iterating over the \(\zeta\)-markup equation from Morrow and Skerlos (2011). Although nontrivial, this fixed point iteration problem is much less demanding than the full optimization routine required to solve the BLP problem from the start.
An empirical distribution of results computed according to this parametric bootstrap procedure can be created with the ProblemResults.bootstrap method, which returns a BootstrappedResults class that can be used just like ProblemResults to compute various post-estimation outputs. The difference is that BootstrappedResults methods return arrays with an extra first dimension, along which bootstrapped results are stacked.
We’ll construct 90% parametric bootstrap confidence intervals for estimated mean own elasticities in each market of the fake cereal problem. Usually, bootstrapped confidence intervals should be based on thousands of draws, but we’ll only use a few for the sake of speed in this example.
[20]:
bootstrapped_results = results.bootstrap(draws=100, seed=0)
bootstrapped_results
[20]:
Bootstrapped Results Summary:
======================
Computation Bootstrap
Time Draws
----------- ---------
00:00:03 100
======================
[21]:
bounds = np.percentile(
bootstrapped_results.extract_diagonal_means(
bootstrapped_results.compute_elasticities()
),
q=[10, 90],
axis=0
)
table = pd.DataFrame(index=problem.unique_market_ids, data={
'Lower Bound': bounds[0].flatten(),
'Mean Own Elasticity': means.flatten(),
'Upper Bound': bounds[1].flatten()
})
table.round(2).head()
[21]:
| Lower Bound | Mean Own Elasticity | Upper Bound | |
|---|---|---|---|
| C01Q1 | -4.31 | -4.21 | -3.88 |
| C01Q2 | -4.07 | -3.96 | -3.68 |
| C03Q1 | -3.71 | -3.40 | -3.20 |
| C03Q2 | -3.65 | -3.34 | -3.16 |
| C04Q1 | -3.31 | -3.15 | -2.97 |
Optimal Instruments¶
Given a consistent estimate of \(\theta\), we may want to compute the optimal instruments of Chamberlain (1987) and use them to re-solve the problem. Optimal instruments have been shown, for example, by Reynaert and Verboven (2014), to reduce bias, improve efficiency, and enhance stability of BLP estimates.
The ProblemResults.compute_optimal_instruments method computes the expected Jacobians that comprise the optimal instruments by integrating over the density of \(\xi\) (and \(\omega\) if a supply side was estimated). By default, the method approximates this integral by averaging over the Jacobian realizations computed under draws from the asymptotic normal distribution of
the error terms. Since this process is computationally expensive and often doesn’t make much of a difference, we’ll use method='approximate' in this example to simply evaluate the Jacobians at the expected value of \(\xi\), zero.
[22]:
instrument_results = results.compute_optimal_instruments(method='approximate')
instrument_results
[22]:
Optimal Instrument Results Summary:
=======================
Computation Error Term
Time Draws
----------- ----------
00:00:00 1
=======================
We can use the OptimalInstrumentResults.to_problem method to re-create the fake cereal problem with the estimated optimal excluded instruments.
[23]:
updated_problem = instrument_results.to_problem()
updated_problem
[23]:
Dimensions:
=================================================
T N F I K1 K2 D MD ED
--- ---- --- ---- ---- ---- --- ---- ----
94 2256 5 1880 1 4 4 14 1
=================================================
Formulations:
===================================================================
Column Indices: 0 1 2 3
----------------------------- ------ -------------- ----- -----
X1: Linear Characteristics prices
X2: Nonlinear Characteristics 1 prices sugar mushy
d: Demographics income income_squared age child
===================================================================
We can solve this updated problem just like the original one. We’ll start at our consistent estimate of \(\theta\).
[24]:
updated_results = updated_problem.solve(
results.sigma,
results.pi,
optimization=pyblp.Optimization('bfgs', {'gtol': 1e-5}),
method='1s'
)
updated_results
[24]:
Problem Results Summary:
=======================================================================================================
GMM Objective Gradient Hessian Hessian Clipped Weighting Matrix Covariance Matrix
Step Value Norm Min Eigenvalue Max Eigenvalue Shares Condition Number Condition Number
---- --------- -------- -------------- -------------- ------- ---------------- -----------------
1 +8.0E-14 +3.0E-06 +1.6E-04 +2.9E+04 0 +7.8E+07 +1.8E+08
=======================================================================================================
Cumulative Statistics:
===========================================================================
Computation Optimizer Optimization Objective Fixed Point Contraction
Time Converged Iterations Evaluations Iterations Evaluations
----------- --------- ------------ ----------- ----------- -----------
00:00:38 Yes 42 50 45893 142156
===========================================================================
Nonlinear Coefficient Estimates (Robust SEs in Parentheses):
=====================================================================================================================
Sigma: 1 prices sugar mushy | Pi: income income_squared age child
------ ---------- ---------- ---------- ---------- | ------ ---------- -------------- ---------- ----------
1 +2.1E-01 | 1 +6.0E+00 +0.0E+00 +1.6E-01 +0.0E+00
(+7.8E-02) | (+5.2E-01) (+2.0E-01)
|
prices +0.0E+00 +3.0E+00 | prices +9.8E+01 -5.6E+00 +0.0E+00 +4.1E+00
(+6.5E-01) | (+8.6E+01) (+4.5E+00) (+2.2E+00)
|
sugar +0.0E+00 +0.0E+00 +2.7E-02 | sugar -3.1E-01 +0.0E+00 +4.9E-02 +0.0E+00
(+7.2E-03) | (+3.5E-02) (+1.3E-02)
|
mushy +0.0E+00 +0.0E+00 +0.0E+00 +3.0E-01 | mushy +9.7E-01 +0.0E+00 -5.4E-01 +0.0E+00
(+1.0E-01) | (+2.9E-01) (+1.8E-01)
=====================================================================================================================
Beta Estimates (Robust SEs in Parentheses):
==========
prices
----------
-3.1E+01
(+4.5E+00)
==========
Optimal Micro Moments¶
Similarly, if we have micro data that links individual choices to demographics, we can use all the information in this data by constructing optimal micro moments that match the score of the micro data, evaluated at our consistent estimate of \(\theta\). See the micro moments tutorial for an introduction to constructing non-optimal micro moments.
We don’t have actual micro data for this empirical example, but we can simulate some just to demonstrate how to construct optimal micro moments. We’ll use the ProblemResults.simulate_micro_data method to simulate 1,000 observations from a micro dataset at the estimated \(\theta\). Like most micro datasets, we’ll define compute_weights such that we only have observations from consumer
who purchase an inside good \(j \neq 0\). For simplicity, we’ll assume we only have micro data from a single market, 'C61Q1'. Again, see the micro moments tutorial for a more in-depth discussion of MicroDataset and micro moments.
[25]:
micro_dataset = pyblp.MicroDataset(
name="Simulated micro data",
observations=1_000,
compute_weights=lambda t, p, a: np.ones((a.size, 1 + p.size)),
market_ids=['C61Q1'],
)
micro_data = results.simulate_micro_data(
dataset=micro_dataset,
seed=0,
)
The simulated micro data are a record array, which can be difficult to visualize. We’ll convert it to a pandas dataframe, which is what we would usually load from an actual micro dataset file.
[26]:
micro_data = pd.DataFrame(pyblp.data_to_dict(micro_data))
micro_data
[26]:
| micro_ids | market_ids | agent_indices | choice_indices | |
|---|---|---|---|---|
| 0 | 0 | C61Q1 | 10 | 24 |
| 1 | 1 | C61Q1 | 14 | 0 |
| 2 | 2 | C61Q1 | 12 | 0 |
| 3 | 3 | C61Q1 | 10 | 21 |
| 4 | 4 | C61Q1 | 8 | 10 |
| ... | ... | ... | ... | ... |
| 995 | 995 | C61Q1 | 1 | 23 |
| 996 | 996 | C61Q1 | 10 | 4 |
| 997 | 997 | C61Q1 | 18 | 0 |
| 998 | 998 | C61Q1 | 4 | 0 |
| 999 | 999 | C61Q1 | 13 | 2 |
1000 rows × 4 columns
The simulated micro data contain four columns:
micro_ids: This is simply an index from \(0\) to \(999\), indexing each micro observation.market_ids: This is the market of each observation. We configured our MicroDatasetto only sample from one market.agent_indices: This is the within-market index (from \(0\) to \(I_t - 1\) in market \(t\)) of the agent data row that was sampled with probability \(w_{it}\), configured by theweightscolumn in agent data.choice_indices: This is the within-market index (from \(0\) to \(J_t - 1\) in market \(t\)) of the produt data row that was sampled with probability \(s_{ijt}\) evaluated at the consistent estimate of \(\theta\).
The simulated data contain a bit more information than we would usually have in actual micro data. The agent_indices contain information not only about observed demographics of the micro observation, but also about unobserved preferences. We will merge in only observed demographics for each agent index to get a more realistic simulated micro dataset.
[27]:
agent_data['agent_indices'] = agent_data.groupby('market_ids').cumcount()
micro_data = micro_data.merge(
agent_data[['market_ids', 'agent_indices', 'income', 'income_squared', 'age', 'child']],
on=['market_ids', 'agent_indices']
)
del micro_data['agent_indices']
micro_data
[27]:
| micro_ids | market_ids | choice_indices | income | income_squared | age | child | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | C61Q1 | 24 | 1.212283 | 22.546328 | 0.624306 | -0.230851 |
| 1 | 1 | C61Q1 | 0 | 0.020036 | -0.519111 | -0.335470 | -0.230851 |
| 2 | 2 | C61Q1 | 0 | -1.106004 | -19.693212 | -1.839547 | 0.769149 |
| 3 | 3 | C61Q1 | 21 | 1.212283 | 22.546328 | 0.624306 | -0.230851 |
| 4 | 4 | C61Q1 | 10 | 0.563580 | 9.643785 | 0.357678 | -0.230851 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 995 | 995 | C61Q1 | 23 | -0.417249 | -8.266351 | 1.273968 | -0.230851 |
| 996 | 996 | C61Q1 | 4 | 1.212283 | 22.546328 | 0.624306 | -0.230851 |
| 997 | 997 | C61Q1 | 0 | -1.106004 | -19.693212 | -0.006965 | -0.230851 |
| 998 | 998 | C61Q1 | 0 | -1.185986 | -20.958686 | 0.851696 | -0.230851 |
| 999 | 999 | C61Q1 | 2 | -0.239006 | -5.154642 | -1.616403 | 0.769149 |
1000 rows × 7 columns
This is more like real micro data that we would actually load from a file. For each observation, we know the market, choice, and demographics of the consumer.
To compute optimal micro moments at our consistent estimate of \(\theta\), we need to compute two types of scores:
The score for each observation in our micro data via ProblemResults.compute_micro_scores.
The score for each possible agent-choice in the model via ProblemResults.compute_agent_scores.
For each, we will integrate over unobserved heterogeneity with quadrature, but one could use Monte Carlo methods too. We will do so by just passing an Integration configuration to these two methods, but we could also do so by duplicating each row of micro data by as many integration nodes/weights we wanted for each, adding weights and nodes columns as with agent data.
[28]:
score_integration = pyblp.Integration('product', 5)
micro_scores = results.compute_micro_scores(micro_dataset, micro_data, integration=score_integration)
agent_scores = results.compute_agent_scores(micro_dataset, integration=score_integration)
Both micro_scores and agent_scores are lists, with one element for each nonlinear parameter in \(\theta\). The ordering is
[29]:
results.theta_labels
[29]:
[np.str_('1 x 1'),
np.str_('prices x prices'),
np.str_('sugar x sugar'),
np.str_('mushy x mushy'),
np.str_('1 x income'),
np.str_('1 x age'),
np.str_('prices x income'),
np.str_('prices x income_squared'),
np.str_('prices x child'),
np.str_('sugar x income'),
np.str_('sugar x age'),
np.str_('mushy x income'),
np.str_('mushy x age')]
The first element of micro_scores corresponds to the \(\sigma\) on the constant term (i.e., the '1 x 1' above). It has the estimated score for each observation in micro_data:
[30]:
micro_scores[0].shape
[30]:
(1000,)
The first element of agent_scores also correspondds to the \(\sigma\) on the constant term. It is a mapping from market IDs to arrays of scores for each of the \(I_t \times J_t\) possible agent-choices in that market.
[31]:
agent_scores[0]['C61Q1'].shape
[31]:
(20, 25)
We will construct one optimal MicroMoment for each parameter, matching the average score (via a MicroPart) for that parameter from the micro data with its model counterpart.
[32]:
optimal_micro_moments = []
for m, (micro_scores_m, agent_scores_m) in enumerate(zip(micro_scores, agent_scores)):
optimal_micro_moments.append(pyblp.MicroMoment(
name=f"Score for parameter #{m}",
value=micro_scores_m.mean(),
parts=pyblp.MicroPart(
name=f"Score for parameter #{m}",
dataset=micro_dataset,
compute_values=lambda t, p, a, v=agent_scores_m: v[t],
),
))
For example, some information about the optimal micro moment for the first parameter is as follows.
[33]:
optimal_micro_moments[0]
[33]:
Score for parameter #0: -2.8E-02 (Score for parameter #0 on Simulated micro data: 1000 Observations in Market 'C61Q1')
Now, we can use our problem with updated optimal IVs, including our optimal micro moments, to obtain an efficient estimator.
[34]:
updated_results = updated_problem.solve(
results.sigma,
results.pi,
optimization=pyblp.Optimization('bfgs', {'gtol': 1e-5}),
method='1s',
micro_moments=optimal_micro_moments,
)
updated_results
[34]:
Problem Results Summary:
=======================================================================================================
GMM Objective Gradient Hessian Hessian Clipped Weighting Matrix Covariance Matrix
Step Value Norm Min Eigenvalue Max Eigenvalue Shares Condition Number Condition Number
---- --------- -------- -------------- -------------- ------- ---------------- -----------------
1 +1.1E+02 +3.8E-06 +2.1E-03 +8.3E+04 0 +2.2E+08 +4.1E+07
=======================================================================================================
Cumulative Statistics:
===========================================================================
Computation Optimizer Optimization Objective Fixed Point Contraction
Time Converged Iterations Evaluations Iterations Evaluations
----------- --------- ------------ ----------- ----------- -----------
00:00:39 Yes 34 42 33341 103798
===========================================================================
Nonlinear Coefficient Estimates (Robust SEs in Parentheses):
=====================================================================================================================
Sigma: 1 prices sugar mushy | Pi: income income_squared age child
------ ---------- ---------- ---------- ---------- | ------ ---------- -------------- ---------- ----------
1 +4.6E-01 | 1 +4.8E+00 +0.0E+00 +6.5E-01 +0.0E+00
(+6.7E-02) | (+3.5E-01) (+1.5E-01)
|
prices +0.0E+00 +3.1E+00 | prices +4.7E+02 -2.5E+01 +0.0E+00 +3.2E+00
(+5.3E-01) | (+3.1E+01) (+1.6E+00) (+1.7E+00)
|
sugar +0.0E+00 +0.0E+00 +2.0E-02 | sugar -4.0E-01 +0.0E+00 +4.6E-02 +0.0E+00
(+6.1E-03) | (+2.4E-02) (+9.2E-03)
|
mushy +0.0E+00 +0.0E+00 +0.0E+00 -6.6E-02 | mushy +1.1E+00 +0.0E+00 -1.1E+00 +0.0E+00
(+8.3E-02) | (+1.9E-01) (+1.1E-01)
=====================================================================================================================
Beta Estimates (Robust SEs in Parentheses):
==========
prices
----------
-5.2E+01
(+2.2E+00)
==========
Estimated Micro Moments:
==============================================================================================================================
Observed Estimated Difference Moment Part Dataset Observations Markets
-------- --------- ---------- ----------------------- ----------------------- -------------------- ------------ -------
-2.8E-02 -2.3E-02 -5.5E-03 Score for parameter #0 Score for parameter #0 Simulated micro data 1000 1
+6.4E-04 +9.8E-04 -3.4E-04 Score for parameter #1 Score for parameter #1 Simulated micro data 1000 1
+1.1E-01 +1.5E-01 -3.4E-02 Score for parameter #2 Score for parameter #2 Simulated micro data 1000 1
-2.9E-04 -3.6E-04 +7.0E-05 Score for parameter #3 Score for parameter #3 Simulated micro data 1000 1
-2.0E-03 +2.1E-02 -2.3E-02 Score for parameter #4 Score for parameter #4 Simulated micro data 1000 1
-3.6E-02 -3.0E-02 -6.3E-03 Score for parameter #5 Score for parameter #5 Simulated micro data 1000 1
-2.5E-04 +2.1E-03 -2.4E-03 Score for parameter #6 Score for parameter #6 Simulated micro data 1000 1
-6.8E-03 +4.0E-02 -4.7E-02 Score for parameter #7 Score for parameter #7 Simulated micro data 1000 1
+1.7E-03 +1.0E-03 +6.8E-04 Score for parameter #8 Score for parameter #8 Simulated micro data 1000 1
+5.5E-02 +1.8E-01 -1.3E-01 Score for parameter #9 Score for parameter #9 Simulated micro data 1000 1
-4.8E-01 -4.7E-01 -1.0E-02 Score for parameter #10 Score for parameter #10 Simulated micro data 1000 1
-2.9E-03 +8.1E-03 -1.1E-02 Score for parameter #11 Score for parameter #11 Simulated micro data 1000 1
-2.6E-02 -5.5E-03 -2.0E-02 Score for parameter #12 Score for parameter #12 Simulated micro data 1000 1
==============================================================================================================================
Results are fairly similar to before because we simulated the micro data from our first-stage estimate of \(\theta\), which was somewhat close to our second-stage estimate. Scores are not matched perfectly because the model is now over-identified, with two times as many moments as there are parameters (one optimal IV and one optimal micro moment for each nonlinear parameter).